

Developer Diary
Selecting an AI cloud provider
When you're selecting an AI provider, OpenAI probably comes first to mind, but it's not necessarily the best choice.

Welcome to the first installment of the hiddenMind Developer Diary! I'm Ed Burnette, CEO of hiddenMind. We've been heads down creating hiddenPersona, our first product, but I thought it was time to come up for air and talk about our progress as we march to General Availability.
Two of the biggest considerations for the product were which model to use and where to host it. We started using OpenAI, which was great for prototyping but the performance was not where we wanted. In addition, it was expensive and the service kept timing out or going down altogether, so we looked around for alternatives. Some that we considered were:
Azure OpenAI. Strangely enough, Microsoft's version is much more reliable than OpenAI's own API. The downsides are that it's even more expensive, they don't get new versions of the models right away, and models are not universally available in all regions.
AWS Bedrock. This would be a good choice for us because the backend is hosted on AWS, resulting in easier maintenance and low latency. Amazon hosts a number of different models including Llama-3, Anthropic, and Cohere. In addition, they have the option of fine-tuning your own model. However, the performance wasn't there.

Anthropic. Speaking of Anthropic, you can get it directly from the vendor, which as we've seen from OpenAI can be a plus or a minus. We did some tests with the Claude 3 Sonnet model, and while it's great for composing and editing text in general, strangely enough it really didn't do as well with persona creation or chats as Llama-3. Llama is better at following directions, and we have pretty long prompts.
Groq (groq.com). Groq runs open source models on specialized hardware they designed, and it's faster than a bat out of, well, you know. While OpenAI averages 25-50 tokens per second, Groq blows that away with 200-300 or more. The difference is night-and-day in an interactive application. Have you noticed how most AI interfaces use streaming so you can see the words as they come back? Groq can do that, but in most applications it doesn't need to because you get the whole answer so quickly.
We did consider hosting it ourselves, but after doing a lot of testing — a lot, trust me — we settled on Groq. Specifically, we use the Llama-3 models they offer. This lets us get the blazing fast speed we need for hiddenPersona at a reasonable cost.
AI inference is something of an arms race right now, and another hot contender is Cerebras. Like Groq, they designed their own chip specifically to run AI, and it pays off in greatly increased speed compared to GPU-based solutions. As of this writing, they claim up to 2,100 tokens per second, or 50-100x the speed of OpenAI.
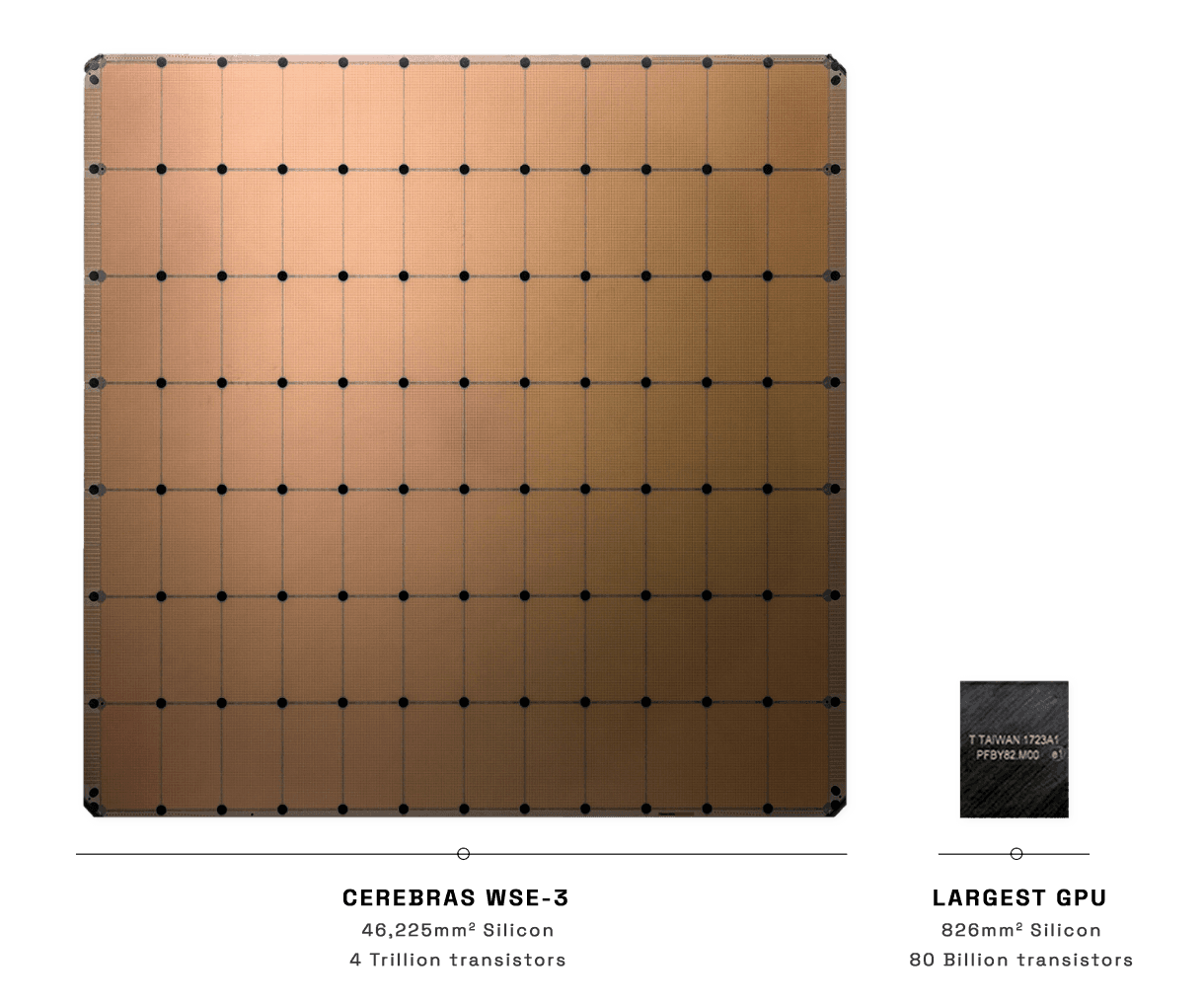
They accomplish this in a unique way by dedicating an entire wafer to the problem. This means faster interconnects and less cluster overhead. In some ways, it's the polar opposite of the approach Groq is taking. I'm looking forward to testing how it stacks up against Groq and other super-fast competitors that are bound to crop up. And because we use open-source models, we can try out the same model on several providers and go with the best at any given time.
Speaking of reliability, we've greatly improved our reliability using a tool called Portkey. I'll have more to say about Portkey in an upcoming episode. That's all for now! And remember, with hiddenMind, you'll always be on the cutting edge. Get started today.